Data Requirements for Predictive Modeling: What You Need to Know
By Philipp Steck & Tomislav Pleško
-
2025
Effective predictive LTV modeling starts with the right data. But what exactly does “good data” for modeling look like?
Churney Data Integration Guide
A technical guide for ensuring accurate and actionable predictive LTV (pLTV) modeling.
1. Introduction & Objective
Our goal is to help you optimize advertising campaigns using predictive Lifetime Value (pLTV) models, improving user acquisition efficiency and return on ad spend (ROAS).
To do this, we need specific raw data from your side. This guide explains:
The data we require for initial sync and ongoing operations
Why each data type matters for model accuracy
Best practices to ensure smooth integration
2. Quick Checklist
Before you start, ensure you can provide the following:
Historical Data: 3–12 months of user and revenue data
Update Frequency: At least daily incremental (append‑only) updates, no full refreshes
Identifiers: A consistent user ID across all tables (mapping table if needed)
Event Logs: Timestamped in UTC with user IDs and revenue fields
Attribution Data: Source of truth for campaign performance (UTM/MMP/ad network)
Format: Raw, minimally transformed data directly from source
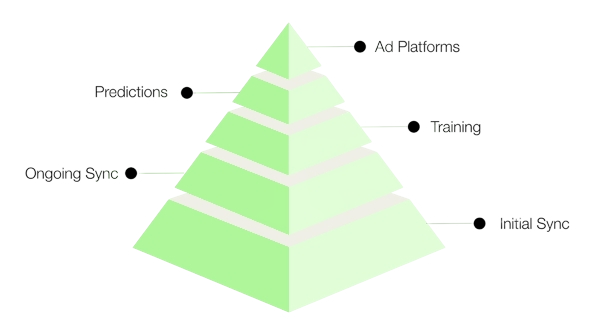
3. Predictive LTV Pipeline
Our pLTV process transforms raw user data into signals for your ad platforms.
Initial Sync
One-time transfer of historical data (3–12 months)
Ongoing Sync
Daily incremental updates to keep models fresh
Model Training & Inference
Build predictive models using historical data
Generate early predictions within hours of user onboarding
Signal Transmission
Send pLTV predictions to ad platforms
Campaign Attribution
Measure campaign performance using attribution data
4. Data Integration Requirements
A) Event Logs
What we need:
Timestamped event data capturing user actions and system telemetry
Business interactions: trial sign‑ups, cancellations, support interactions
User actions: add to cart, game progress, newsletter sign‑ups
Telemetry: sessions, app opens, page views
Format Example:
json
CopyEdit
{
"event_timestamp": "2025-07-28T14:22:15Z",
"event_name": "purchase",
"user_id": "abc123",
"revenue": 12.99,
"device_os": "iOS",
"country": "US"
}
Key Rules:
Must include at minimum: event_timestamp, event_name, user_id;
Revenue events should include a revenue field;
Provide all available context columns (device, country, channel, etc.);
Deliver as raw logs (e.g., Firebase/GA4 format).
B) User-Level Data
What we need:
Attributes tied to each user: demographics, device info, registration details
Usage:
Feature generation for modeling;
Regional and platform-specific model adjustments.
Format Example:
json
CopyEdit
{
"user_id": "abc123",
"registration_date": "2025-01-10",
"country": "US",
"device_os": "Android",
"age_group": "25-34",
"signup_channel": "Facebook Ads"
}
C) User Identifiers
What we need:
Identifiers for linking users to ad platforms / MMPs
Examples:
Device IDs: IDFA (iOS), GAID (Android)
MMP IDs: Appsflyer ID / Singular ID /Adjust ID
PII (Hashed): email, phone number (SHA‑256 hashing recommended)
Location: IP, country, postal code
Note: If multiple IDs exist, provide a mapping table that ensures a consistent user_id across all datasets.
D) Campaign Attribution Data
What we need:
User acquisition details (campaign, channel, platform)
Examples of attribution sources:
UTM parameters;
Ad network identifiers;
Mobile Measurement Partners (Appsflyer, Singular, Adjust);
Usage:
Measures campaign ROI and validates pLTV accuracy
Ensures alignment with your attribution models
--
To summarize, below you may find a Diagram of core variables we need. For a deeper dive into table structures and vertical-specific examples, check out our Data Schema Examples.
5. General Requirements
Refresh Frequency: Daily (≤24h latency);
Update Mechanism: Incremental append-only updates (no overwrites or full refreshes);
Data Format: Raw, minimally transformed, no derived features from future events;
Partitioning: Partition tables by date for efficiency.
6. Data Quality Standards
Timestamps: Always in UTC (ISO‑8601 format preferred);
Consistency: One reliable user ID across event, user, attribution, and payment tables;
Append-Only Policy: Never mutate historical data; append new records;
Partitioning: Use daily partitions for incremental updates.
7. Common Pitfalls & How to Avoid Them
Inconsistent IDs → Provide mapping logic across tables
Missing Events → Include all relevant activity, not just purchases
Data Mutations → Avoid overwriting past records (causes model leakage)
Full Refreshes → Use incremental append-only updates instead
Attribution Misalignment → Share your attribution methodology with us upfront
8. Support
If you cannot fully meet these requirements, we can connect you with a Churney Data Partner who will handle end‑to‑end cleanup and setup (typically within ~3 weeks). Contact your Churney point of contact for assistance.
Optimize your customer acquisition for maximum Lifetime Value
Your data warehouse has incredible value. Our causal AI helps unlock it.

.png)
